
Künstliche Intelligenz in der Posteingangsverarbeitung
Durch den Einsatz von Künstlicher Intelligenz (KI) soll das Leben im Unternehmensalltag erleichtert werden. Ein Beispiel ist der Einsatz von intelligenten Mechanismen in der Posteingangsverarbeitung, von dem insbesondere Unternehmen mit viel Kundenkontakt profitieren können. Durch KI wird das händische Vor- und Einsortieren der Nachrichten automatisiert und somit der Kundenservice effizienter gemacht.
Früher war klar: Wer Unterlagen beispielsweise an eine Behörde oder ein Versicherungsunternehmen sendet, macht dies per Post oder per Fax. Heutzutage verschicken viele Kund*innen oder Versicherte ihre Dokumente per Mail oder laden sie gleich in ein Kundenportal hoch.
Damit nun diese verschiedenen Eingangskanäle nicht alle manuell überprüft und einzeln betreut werden müssen, gibt es sogenannte Omnichannel-Dokumentenmanagementsysteme. Wir beziehen uns im Folgenden auf das System smart FIX des Herstellers Insiders Technologies GmbH [tec2022].
Das smart FIX-System dient zur Verarbeitung von Dokumenten, um zum einen deren spezifische Dokumentklasse zu bestimmen und zum anderen die auf dem Dokument aufgebrachten Informationen für die Nachfolgesysteme auszulesen. Hierbei durchlaufen alle Dokumente im smart FIX-System einen definierten internen technischen Workflow. Die KI-Mechanismen in smart FIX greifen im Workflow-Schritt der Dokumentenklassifikation und der Informationsextraktion.
KI-Mechanismen in der Dokumenteneingangsverarbeitung
Hier soll nun eine Auswahl an verwendeten KI-Mechanismen vorgestellt werden, die im Rahmen der Dokumenteneingangsverarbeitung heutzutage verwendet werden.
Intelligente Algorithmen
In den Anfangsjahren der KI wurden im smart FIX System intelligente Algorithmen umgesetzt, die heute noch zum Tragen kommen. Hierzu zählen beispielsweise die „Wortsegmentierung“. Diese hilft, Wortgrenzen der ausgelesenen Zeichen auf den Dokumenten zu identifizieren und somit vollständige Wörter zu bilden.
Ein weiterer intelligenter Algorithmus ist die „TopDown-Suche“. Hierbei werden die Inhalte der Validierungsdatenbank im übertragenen Sinne auf das Dokument gelegt und dort gesucht. Bei der Suche werden diverse Schwellwerte berücksichtigt, anhand derer die Entscheidung vom System getroffen werden kann, welcher Datensatz der richtige ist. In Freiform-Schreiben wird über diese Methode der Geschäftspartner (z.B. versicherte Person) identifiziert.
Darüber hinaus bietet das smart FIX-System eine Fuzzy-Datenbanksuche an, sodass auch „unscharfe“ Datenbankabfragen zu einem erfolgreichen Datenbankabgleich führen [itwiss2021].
Regelbasierte Systeme
Das smart FIX-System nutzt für das Lernen von Feldern das „fallbasierte Schließen“ (engl. case-based reasoning, CBR) ([ert2016] S. 215). Bei dieser KI-Methode werden mit Hilfe von zuvor erzeugten Lerndaten, die das LearnModule des smart FIX-Systems im laufenden Betrieb erzeugt, Vorgehensweisen aus Erfahrungswerten für die Verarbeitung von Dokumenten abgeleitet. Somit handelt es sich bei dieser Technik um ein sogenanntes Online-Training.
Die Strategie, wie gelernt wird, wird dabei für jedes auszulesende Feld auf einer technischen Dokumentklasse in smart FIX konfiguriert. Als Strategien gibt es beispielsweise die erwartete Feldposition oder auch Schlüsselwörter, die in der Regel beim auszulesenden Feld mit aufgedruckt sind. Weiterhin kann auch der reguläre Ausdruck, der den Aufbau des Feldinhaltes bestimmt, automatisiert vom System gelernt werden.
Maschinelles Lernen
Das maschinelle Lernen wird im smart FIX-System unter anderem im Bereich der automatischen Dokumentklassifikation mit Hilfe des AutoClassifiers eingesetzt. Der AutoClassifier nutzt als Lernverfahren die logistische Regression [camp2021]. Mit Hilfe des AutoClassifiers wird auf Basis charakteristischer Wörter und Phrasen eine inhaltsbasierte Klassifikation der Dokumente vorgenommen. Hierbei wird das System zunächst mit nach Dokumentklassen sortierten Trainingsbildern trainiert. Das Training wird dann mit Hilfe der Testmenge geprüft. Durch Einsatz einer sogenannten Erweiterungsmenge kann der Klassifikator dann nachtrainiert werden, falls er Klassen nicht sauber voneinander trennen kann. Durch den Einsatz des Active Learnings [camp2021] sammelt das System automatisch passende Dokumente, die für die Erweiterungsmenge sinnvoll sind. Das smart FIX-System entscheidet dabei selbst, welche Dokumente passen und welche nicht.
Neben der automatischen Dokumentklassifikation bietet das smart FIX-System auch die automatische Dokumenttrennung an. Bei der automatischen Dokumenttrennung erlernt das System eigenständig die Dokumentgrenzen auf Basis einer definierten Trainingsmenge. Als Lernverfahren kommen hierbei die Support Vector Machine (SVM) ([ert2016] S 296) und die Active Noise Correction zum Einsatz. Beim Training werden für jede Seite verschiedene inhaltliche und optische Merkmale ausgewertet, anhand derer das System entscheiden kann, ob die aktuelle Seite zum vorherigen Dokument gehört, oder ob ein neues Dokument beginnt. Wie auch beim AutoClassifier findet bei der automatischen Dokumenttrennung unter Einsatz des Active Learnings [camp2021] eine intelligente Sammlung von geeigneten Bildstapeln statt.
Sowohl der AutoClassifier als auch die automatische Dokumenttrennung sind keine selbstlernenden KI-Mechanismen, was bedeutet, dass es sich bei diesen Methoden um ein sogenanntes Offline-Training handelt. Das Neutrainieren des AutoClassifiers und der automatischen Dokumenttrennung findet somit im Rahmen der Weiterentwicklung des smart FIX-Systems statt. Hierbei können dann die durch das Active Learning [camp2021] gesicherten Daten ausgewertet und für ein Neutraining herangezogen werden.
Die KI „OVATION“
Das smart FIX-System bietet darüber hinaus die Möglichkeit, Deep Learning-Strategien durch Einsatz der Insiders KI „OVATION“ anzubinden. Hierbei werden von OVATION mehrschichtige neuronale Netze für das System bereitgestellt. Der sogenannte OVATION-Server stellt für jedes neuronale Netz einen Dienst bereit, um auf dieses Netz zugreifen zu können. So kann er beispielsweise einen Dienst zur bildbasierten Ausweiserkennung anbieten. Auch ist es möglich, mit Hilfe eines neuronalen Netzes eine KI-basierte Bildbereinigung vorzunehmen, sodass die OCR der Dokumente besser ausgelesen werden kann. Auf den beiden folgenden Bildern ist die klassische Binarisierung mit dem Ergebnis aus der Bildbereinigung unter Einsatz von Deep Learning dargestellt (Bildquellen: [tec2021])
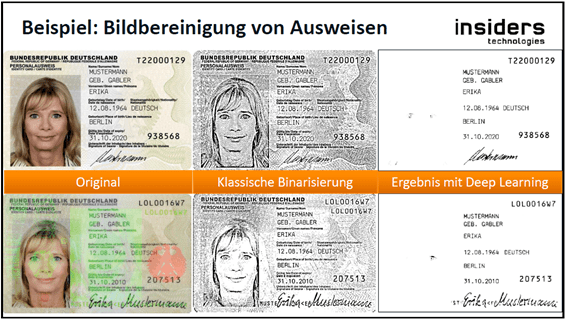
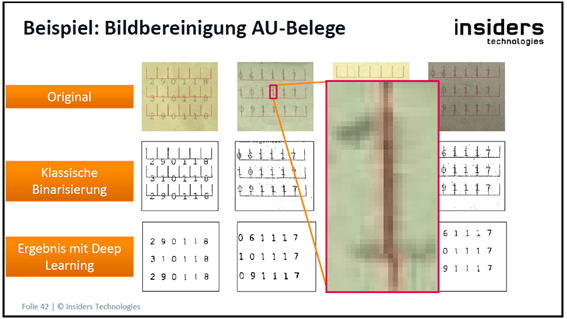
Das Training eines solchen neuronalen Netzes erfolgt in der Regel durch Insiders. Zur Erstellung eines neuronalen Netzes werden neben geeigneter Hardware mit entsprechenden Grafikprozessoren auch entsprechende Softwarekomponenten benötigt, die im Regelfall in den Kundeninstallationen nicht vorhanden sind.
Durch Einsatz eines OVATION-Servers besteht die Möglichkeit, den traditionellen AutoClassifier (siehe Kapitel „Maschinelles Lernen“) dahingehend zu erweitert, dass nicht nur textbasiert, sondern auch bildbasiert die Dokumente klassifiziert werden können. Der sogenannte Cognitive Classifier wird hierbei wie der normale AutoClassifier direkt in smart FIX trainiert. Ein externes Training durch Insiders ist hier nicht erforderlich. Das beim AutoClassifier eingesetzte Lernverfahren der logistischen Regression wird durch Deep Learning für die Erkennung der optischen Merkmale erweitert.
Literatur:
[ert2016] Wolfgang Ertel, Grundkurs Künstliche Intelligenz, Springer Vieweg, 2016
[tec2021] Insiders Technologies, Lernmechanismen in smart FIX, 2021
[tec2022] https://insiders-technologies.com/de
[camp2021] https://www.datacamp.com/community/tutorials/active-learning, Zuletzt besucht am 28.12.2021
[itwiss2021] https://www.itwissen.info/Fuzzy-Suche-fuzzy-search.html Zuletzt besucht am 28.12.2021
Über den Autor:
Markus Distelrath, seit 2016 bei der CONITAS als Entwickler und Berater im Team IMS tätig. Zuvor seit 2008 Mitarbeiter bei Insiders Technologies GmbH.
Titelbild: fatido/iStock